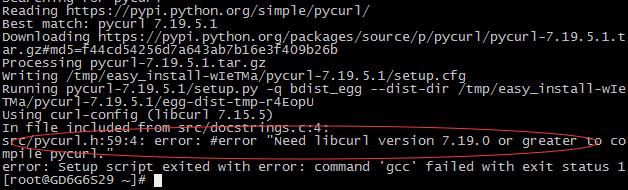
安装pycurl,提示libcurl的库文件太旧,无法安装。
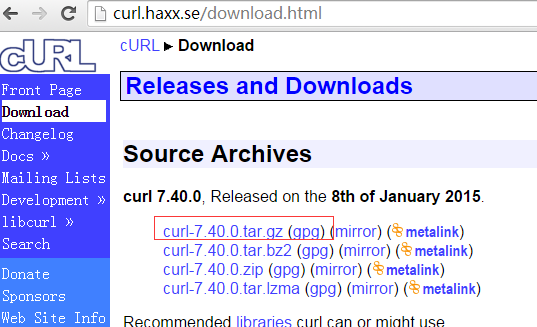
下载libcurl进行编译,http://curl.haxx.se/download/curl-7.40.0.tar.gz
http://curl.haxx.se/download.html
经编译并安装libcurl库后,使用pip install pycurl,则完成相关包了。
————————————————
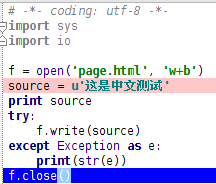
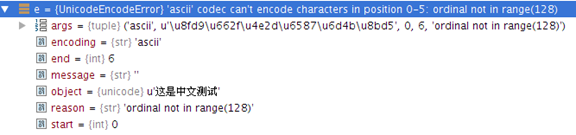
测试pycurl是否安装成功,提示错误:

import pycurl
undefined symbol: curl_multi_socket_action
这是由于使用了错误的连接库而产生的,错误的连接库有如下几种可能。
1.系统存在多个相应的同名链接库,导致使用错误的链接库。
2.编译参数设置不对,导致编译时没有把必须的组件编译进动态库中。
3.所依赖的库,依赖了更多的其它项,这些项缺失或丢失。
解决这问题的直接方法是检查目标程序或动态库所有依赖项是否符合预期。检查连接库的命令是:
ldd (library dynamic detect)
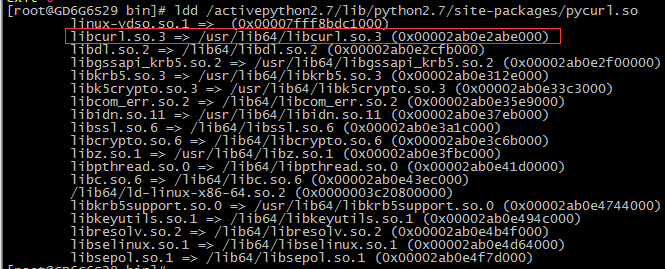
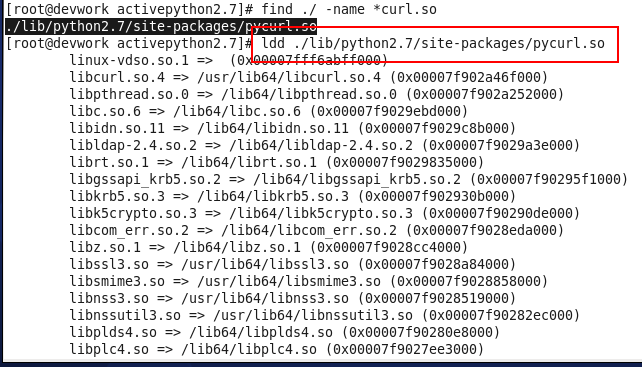
pycurl.so问题,指向了一个libcurl.so.3的版本,故是错误版本。正确的链接版本是libcurl.so.4如下图所示。
解决问题的办法,如果按照传统的以下四种办法是不一定能解决的,这是因为如下办法是只适用于标准的configure+make方式编译和链接的,如下图所示:
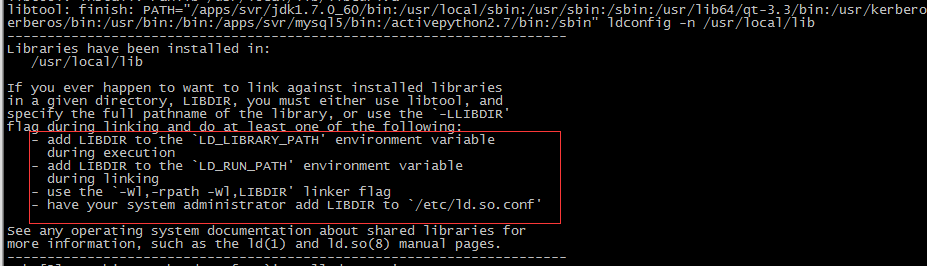
– add LIBDIR to the `LD_LIBRARY_PATH’ environment variable during execution
– add LIBDIR to the `LD_RUN_PATH’ environment variable during linking
– use the `-Wl,-rpath -Wl,LIBDIR’ linker flag
– have your system administrator add LIBDIR to `/etc/ld.so.conf’
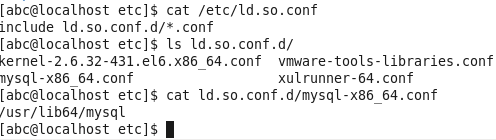
为了避免后续有提示libcurl.so.4找不到,从而加载失败的情况,需要把/usr/local/lib动态库加入到/etc/ld.so.conf中。按以下方法
1./sbin/ldconfig
2.echo ‘/usr/local/lib’ >> /etc/ld.so.conf
3./sbin/ldconfig更新连接缓存信息。
而python的包管理工具,是可以调用gcc编译程序,那是否包的setup.py指名了编译详细办法呢???
分析setup.py的出错信息
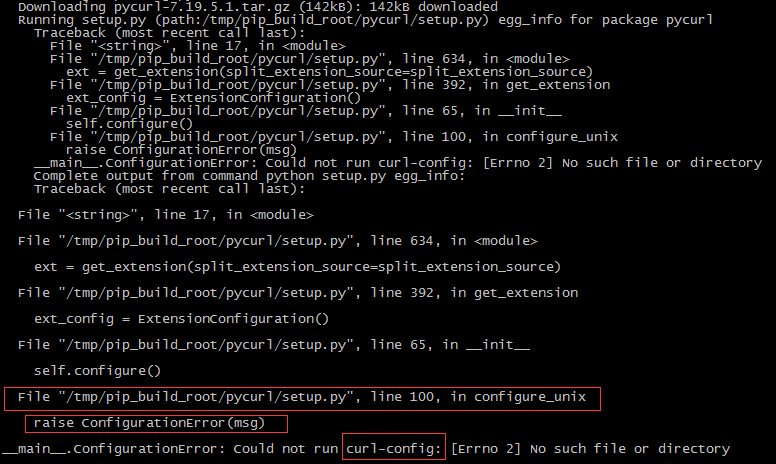
指向setup.py源码100行位置,在其附近我们找到了关键线索PYCURL_CURL_CONFIG。
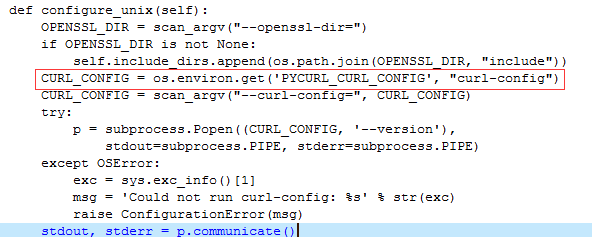
在百度上搜索该关键环境变量,我们知道它是指向一个叫curl-config的文件,在linux标准编译环境内,xxx-config是由configure命令生成的目标程序的配置文件,常包括程序安装位置以及头文件和连接库的信息,它在调用make install命令后,它应该会与执行程序存放在一起,故在源代码目标可找到该配置文件,如下图所示:
开始设置环境变量并编译:
export PYCURL_CURL_CONFIG=/home/apps/curl-7.19.7/curl-config
pip install pycurl
仍然出现如下悲剧错误:
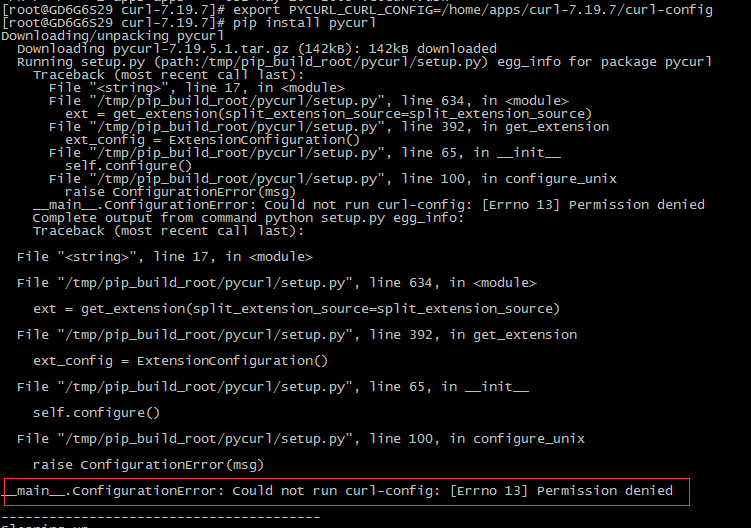
我们进一步分析错误原因,显然这个文件是找到但因权限不足而不允许执行,这原因仍然要看setup.py源码。如下图:
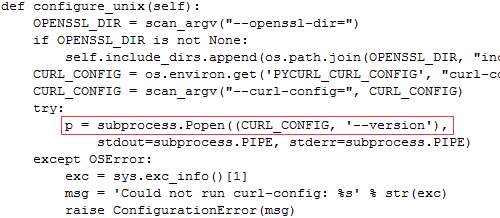
它是把这个PYCURL_CURL_CONFIG指导向的文件,当作一个可执行程序进行操作,并传入一个参数:–version,所以应该是配置文件本身属性问题。

这说明它不是一个执行文件,因为curl-config是一段脚本程序,我们为它添上可执行文件的属性。
chmod a+x curl-config

已经可以返回版本的结果了,再次执行如下命令。
export PYCURL_CURL_CONFIG=/home/apps/curl-7.19.7/curl-config
pip install pycurl
终于顺利完成。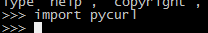
全过程最终使用的源码,是根据centos6.5的软件源提示而从网上下载的,这样做的主要目的自认为与centos6.5一致,可避名因为包的不兼容而产生种种希奇古怪的问题。
pycurl-7.19.5.1.tar.gzhttps://pypi.python.org/packages/source/p/pycurl/pycurl-7.19.5.1.tar.gz#md5=f44cd54256d7a643ab7b16e3f409b26b
curl-7.19.7.tar.gzhttp://curl.haxx.se/download/archeology/curl-7.19.7.tar.gz