1.下载合适的solr版本。当前官网最新版本是6.4.1,但经验证,6.4.1版本在其管理后台中操作dataimport时,会显示空白页。故本人不建议使用最新版本进行学习和应用开发。经验证,其5.5.3版本的各项功能是可以正常工作的。
下载5.5.3版本,快捷路径是:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr
http://lucene.apache.org/solr/mirrors-solr-latest-redir.html
选择任意一个镜像,在进入镜像后,选择parent目录。

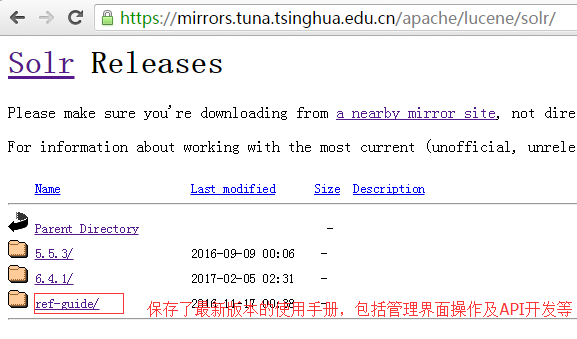
选择5.5.3的版本:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/5.5.3/
https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/5.5.3/solr-5.5.3.zip
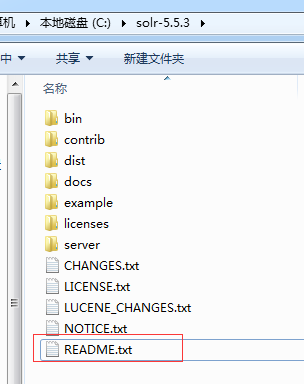
2.如下是其目录结构,初学者,应该习惯阅读Readme.txt文件,该文件记录了一些基本使用操作,很方便学习。
3.内置了几个例子,需要使用特殊命令开启,初学者应该每个例子都体验一下。
bin/solr -e where is one of:
cloud : SolrCloud example
dih : Data Import Handler (rdbms, mail, rss, tika)
schemaless : Schema-less example (schema is inferred from data during indexing)
techproducts : Kitchen sink example providing comprehensive examples of Solr features
4.体验dih例子。
bin/solr -e dih
5.打开管理后台页面:
在实际测试过程中,发现在window中,dataimport等一些相关操作,会失败。只有linux的才会成功,具体原因没有去分析。
http://mysql.mvware.com:8983/solr/
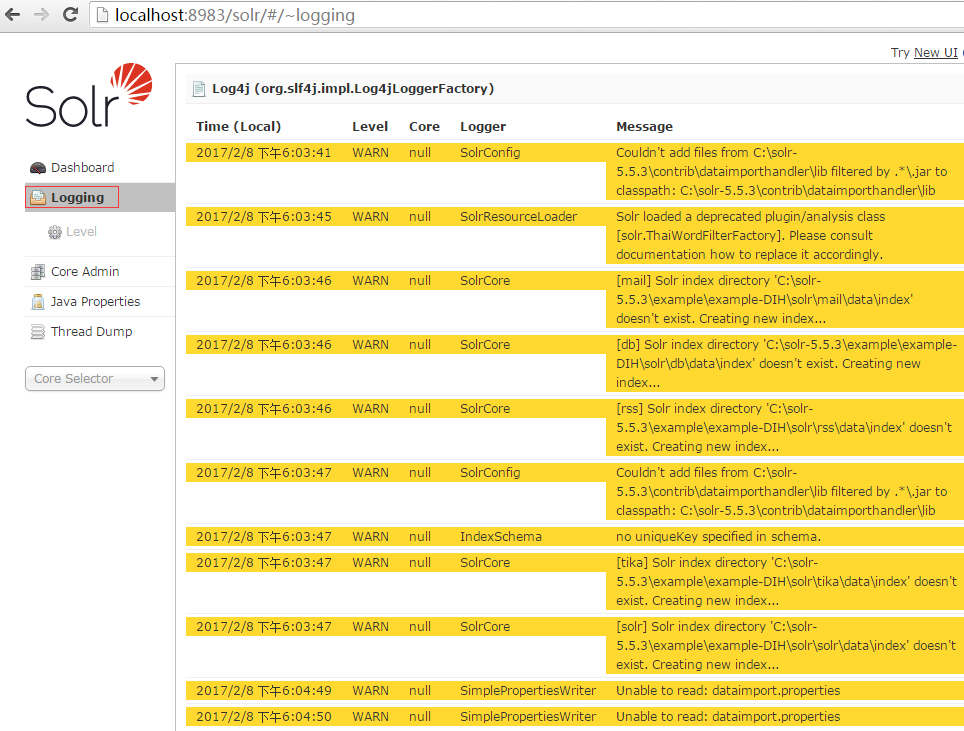
6.logging界面,当执行dataimport或其它操作,如果有错误或执行失败,可以检查该日志信息。
7.在CoreSelector中选择solr项,并选择dataimport项.
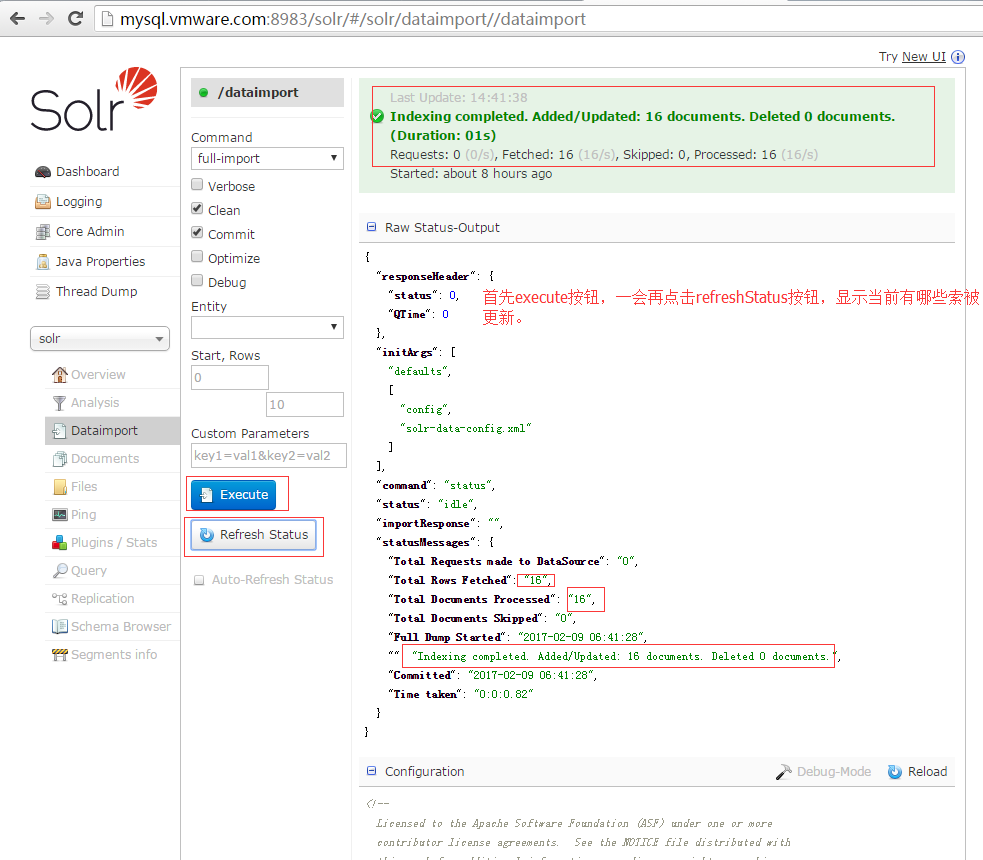
8.在dataimport项中,调试你的配置文件,经过该步骤,已经可以在query项和schemabrowser项中查询到相关记录了。
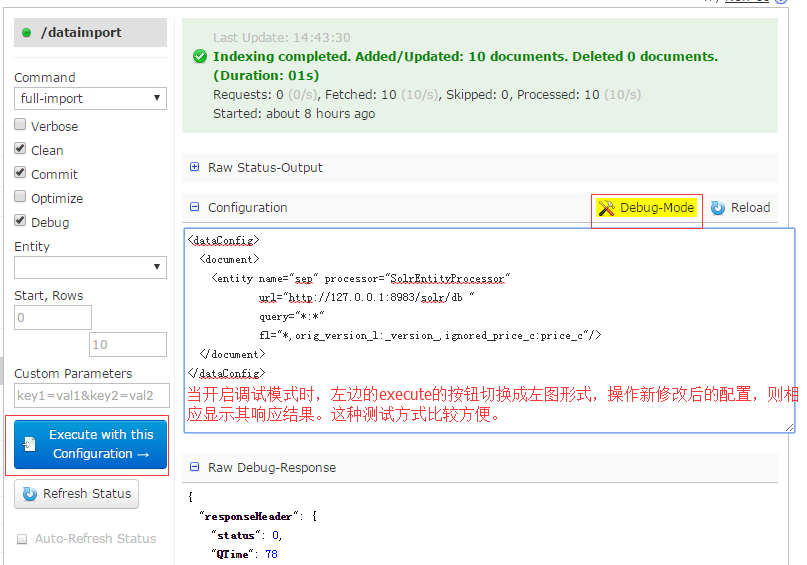
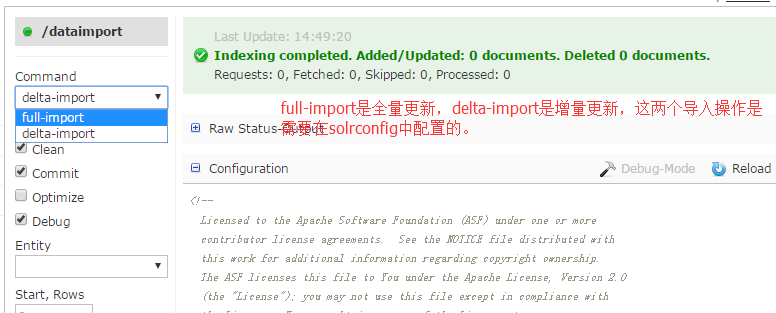
9.在dataimport项中,执行全量更新和增量更新,dataimport项是需要在solrconfig.xml中配置的。
solrconfig.xml中的requestHandler配置
solr-data-config.xml
solr-data-config.xml中的配置
10.浏览schemabrowser中的各个schema项,在solr6.x版本中,增加了schema的增删项,更方便从零搭建core项。
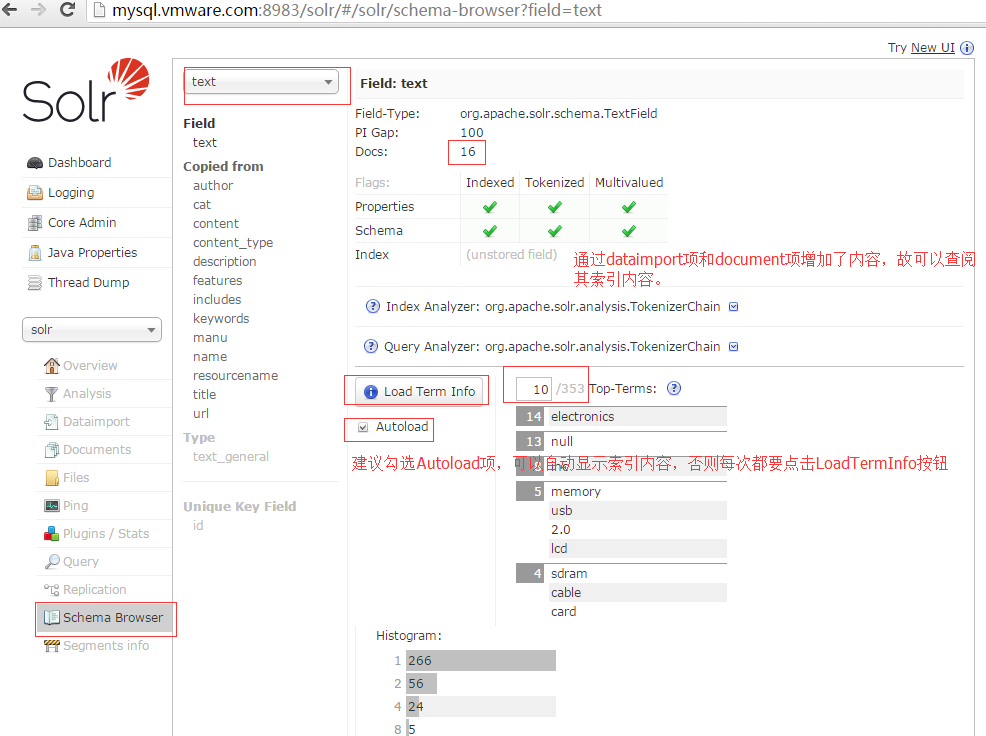
11.通过documents项,增加数据记录,通过schemabrowser或manage-schema.xml配置文件中可知道当前的schema有如下:。
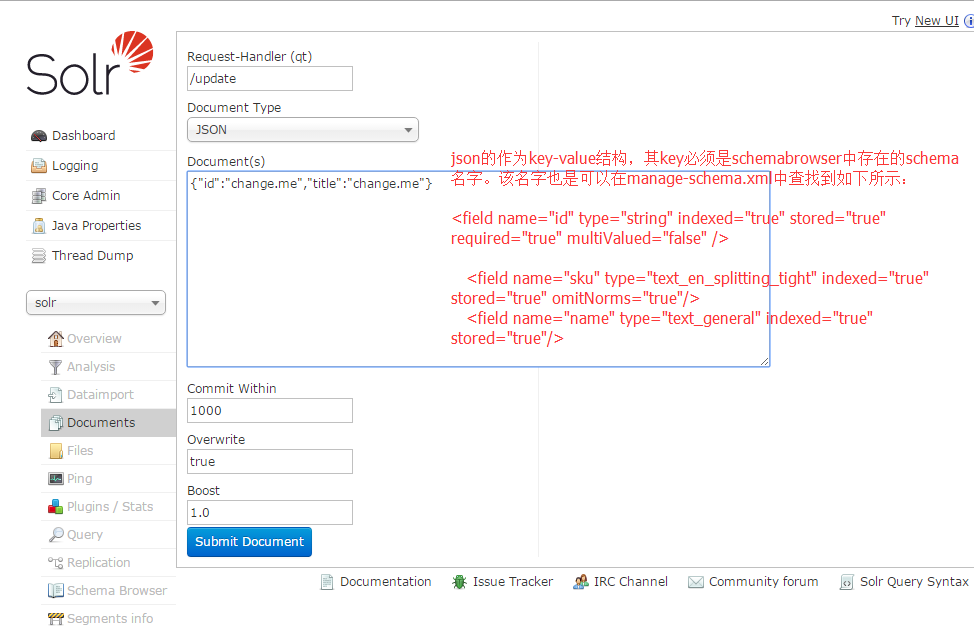
在DocumentType选择JSON项,然后输入内容如下,并点击submit按钮提交:
{"id":12345, "author":"author_121","text":"text_121", "title":"title_1121"}
{"id":22345, "url":"url_121"}
如果执行成功,则提示如下:
Status: success
Response:
{
"responseHeader": {
"status": 0,
"QTime": 2
}
}
如果出错呢?也会有相应的错误提示,可依据提示进行修改输入项内容。

12.通过query项,进行查找刚才的输入项。
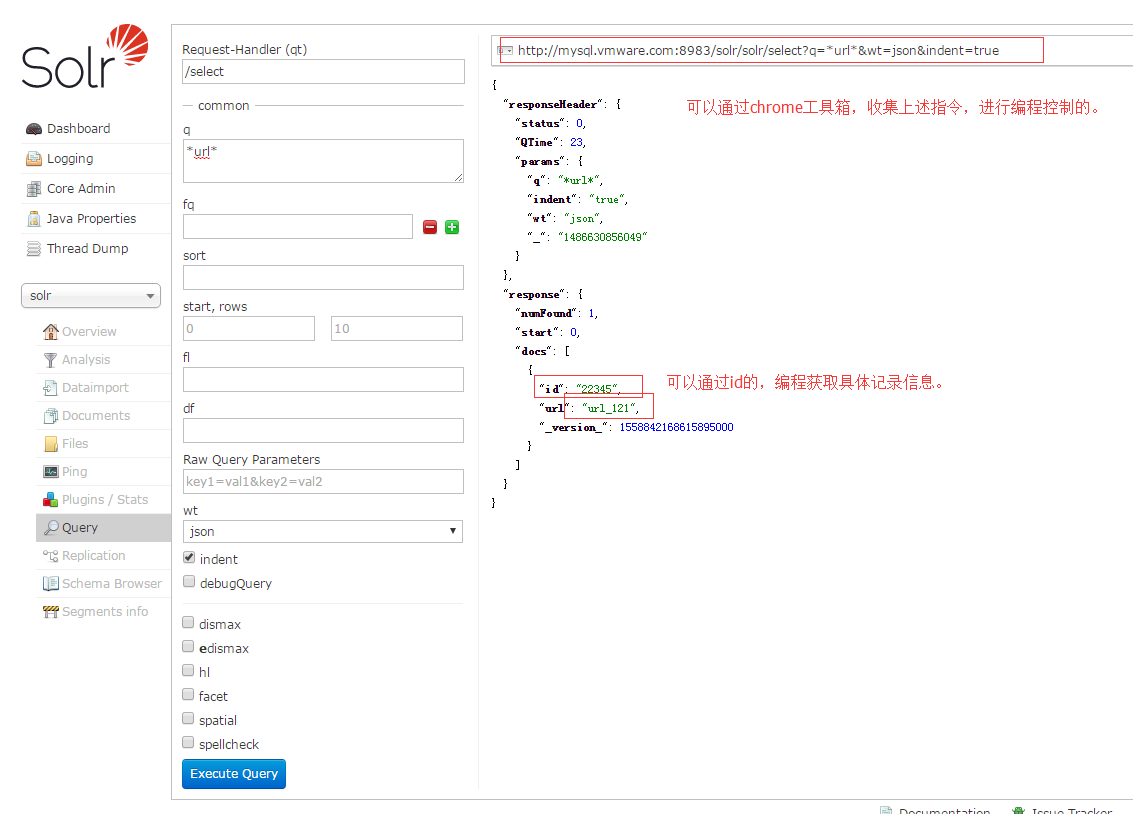
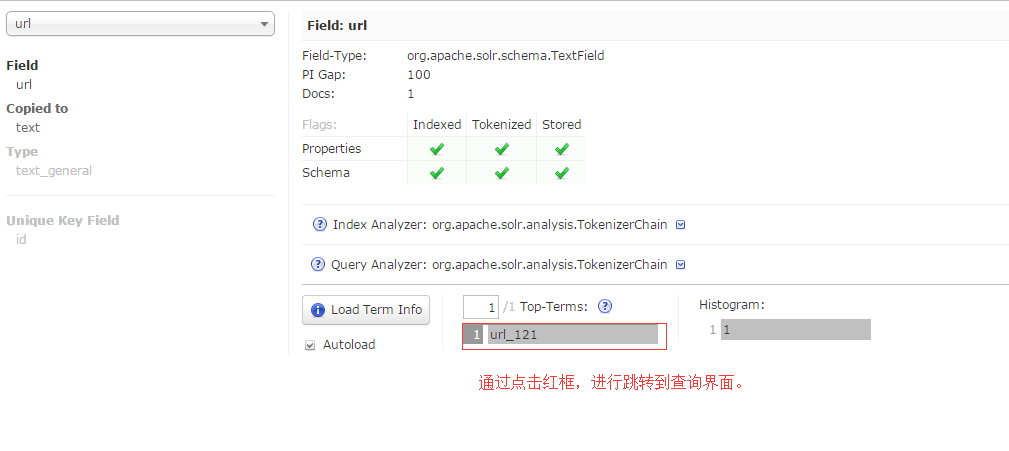
13.也可以通schemabrowser中的记录,快速跳转搜索的内容。

![095511iaj6jwflj4u6l4jr[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095511iaj6jwflj4u6l4jr1.jpg)
![095514uu57wz5m7tkuwj5j[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095514uu57wz5m7tkuwj5j1.jpg)
![095517mnembeesm8m3mq4d[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095517mnembeesm8m3mq4d1.jpg)
![095520iz9uzsevw4epvk9x[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095520iz9uzsevw4epvk9x1.jpg)
![095523ajdnqoaady0bjqy7[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095523ajdnqoaady0bjqy71.jpg)
![0955263sa6jajsh8naa53o[1]](http://www.kxtry.com/wp-content/uploads/2016/08/0955263sa6jajsh8naa53o1.jpg)
![0955295rpiwp5z11izelzz[1]](http://www.kxtry.com/wp-content/uploads/2016/08/0955295rpiwp5z11izelzz1.jpg)
![095532bk070rs74ksprb03[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095532bk070rs74ksprb031.jpg)
![095534od45ii5o3o55x3rm[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095534od45ii5o3o55x3rm1.jpg)
![095538pcb1al72aca4c7h2[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095538pcb1al72aca4c7h21.jpg)
![095540qnrrnbb18jb9ljfl[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095540qnrrnbb18jb9ljfl1.jpg)
![09554511y01n3xs0my3mvc[1]](http://www.kxtry.com/wp-content/uploads/2016/08/09554511y01n3xs0my3mvc1.jpg)
![095547800q00qee0frf0kx[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095547800q00qee0frf0kx1.jpg)
![095549ozmdocos6xcd6mas[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095549ozmdocos6xcd6mas1.jpg)
![095552sjavwsguwqw10z1g[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095552sjavwsguwqw10z1g1.jpg)
![095553cocalcc1msmwmrog[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095553cocalcc1msmwmrog1.jpg)
![095556ezy46sf4ossytfty[1]](http://www.kxtry.com/wp-content/uploads/2016/08/095556ezy46sf4ossytfty1.jpg)