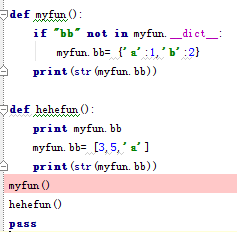
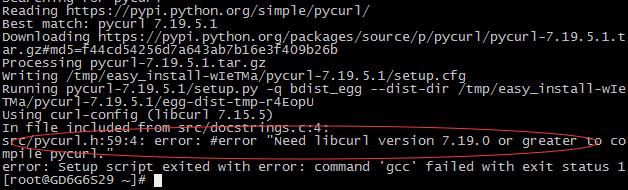
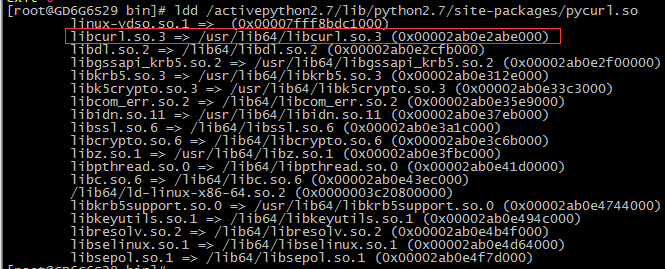
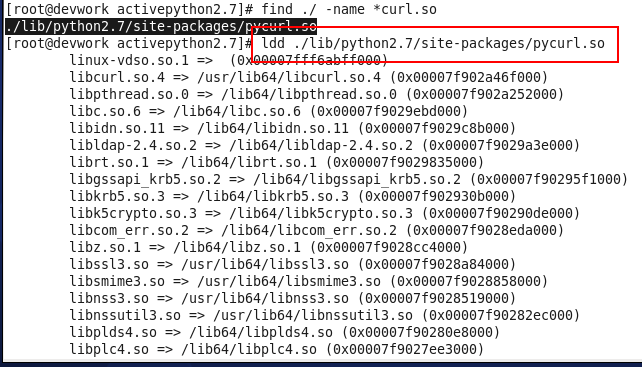
Twisted 15.0 appears to have changed the signature of the _getEndpoint method on twisted.web.client.Agent. This causes the http11 handler to throw exceptions like so:
Traceback (most recent call last):
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/core/downloader/middleware.py”, line 38, in process_request
return download_func(request=request, spider=spider)
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/core/downloader/__init__.py”, line 123, in _enqueue_request
self._process_queue(spider, slot)
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/core/downloader/__init__.py”, line 143, in _process_queue
dfd = self._download(slot, request, spider)
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/core/downloader/__init__.py”, line 154, in _download
dfd = mustbe_deferred(self.handlers.download_request, request, spider)
—
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/utils/defer.py”, line 39, in mustbe_deferred
result = f(*args, **kw)
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/core/downloader/handlers/__init__.py”, line 40, in download_request
return handler(request, spider)
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/core/downloader/handlers/http11.py”, line 36, in download_request
return agent.download_request(request)
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/scrapy/core/downloader/handlers/http11.py”, line 174, in download_request
d = agent.request(method, url, headers, bodyproducer)
File “/usr/share/python/spotify-prelude2-directed-crawlers/local/lib/python2.7/site-packages/twisted/web/client.py”, line 1560, in request
endpoint = self._getEndpoint(parsedURI)
exceptions.TypeError: _getEndpoint() takes exactly 4 arguments (2 given)
That method’s signature in Twisted 15.0.0 is def _getEndpoint(self, uri): while in version 14.0.2 it isdef _getEndpoint(self, scheme, host, port):