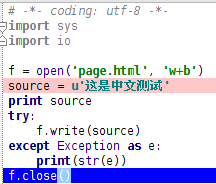
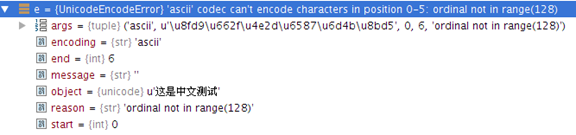
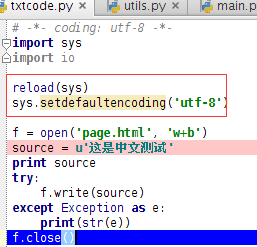
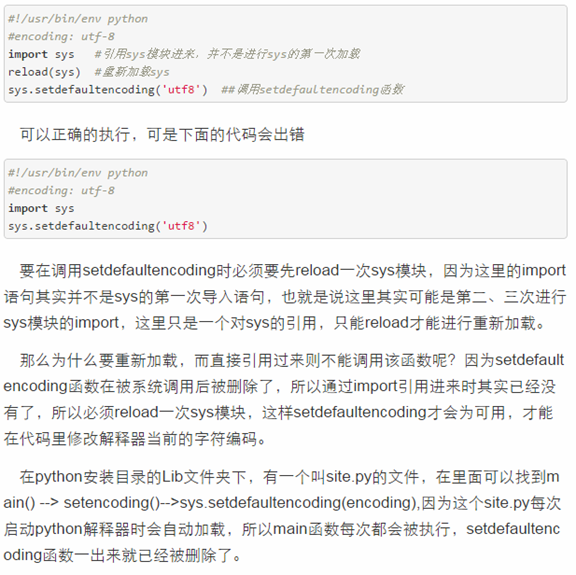
经过测试和源码分析,证实scrapy是单线程异步模式进行工作。
start t = 1421317312.693043 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/1
end t = 1421317312.693043 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/1
2015-01-15 02:21:52-0800 [dmoz] DEBUG: Crawled (200) <GET http://www.baidu.com/1> (referer: None)
2015-01-15 02:21:52-0800 [dmoz] DEBUG: Crawled (200) <GET http://www.baidu.com/2> (referer: None)
start t = 1421317312.697041 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/2
end t = 1421317312.697041 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/2
xxxxxxxxxxxxxxxxxxxxxxxxxxx
————parse t = 1421317312.699310 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/1
start t = 1421317370.153754 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/3
end t = 1421317370.153754 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/3
————parse t = 1421317370.156391 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/2
2015-01-15 02:22:50-0800 [dmoz] DEBUG: Crawled (200) <GET http://www.baidu.com/3> (referer: None)
start t = 1421317370.171718 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/4
end t = 1421317370.171718 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/4
————parse t = 1421317370.175629 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/3
2015-01-15 02:22:50-0800 [dmoz] DEBUG: Crawled (200) <GET http://www.baidu.com/4> (referer: None)
start t = 1421317370.194542 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/5
end t = 1421317370.194542 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/5
————parse t = 1421317370.197380 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/4
2015-01-15 02:22:50-0800 [dmoz] DEBUG: Crawled (200) <GET http://www.baidu.com/5> (referer: None)
start t = 1421317370.213179 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/6
end t = 1421317370.213179 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/6
————parse t = 1421317370.216034 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/5
2015-01-15 02:22:50-0800 [dmoz] DEBUG: Crawled (200) <GET http://www.baidu.com/6> (referer: None)
start t = 1421317370.230415 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/7
end t = 1421317370.230415 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/7
————parse t = 1421317370.233487 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/6
2015-01-15 02:22:50-0800 [dmoz] DEBUG: Crawled (200) <GET http://www.baidu.com/7> (referer: None)
start t = 1421317370.249530 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/8
end t = 1421317370.249530 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/8
————parse t = 1421317370.252307 thread id <property object at 0x7faab1e4be10>, http://www.baidu.com/7