1.下载docker镜像库:https://github.com/big-data-europe/docker-hive.git,并安装它。
2.修改其docker-compose.yml文件,为每个容器增加上映射。
version: "3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop2.7.4-java8
volumes:
- /data/namenode:/hadoop/dfs/name
- /data/tools:/tools
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop-hive.env
ports:
- "50070:50070"
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop2.7.4-java8
volumes:
- /data/datanode:/hadoop/dfs/data
- /data/tools:/tools
env_file:
- ./hadoop-hive.env
environment:
SERVICE_PRECONDITION: "namenode:50070"
ports:
- "50075:50075"
hive-server:
image: bde2020/hive:2.3.2-postgresql-metastore
volumes:
- /data/tools:/tools
env_file:
- ./hadoop-hive.env
environment:
HIVE_CORE_CONF_javax_jdo_option_ConnectionURL: "jdbc:postgresql://hive-metastore/metastore"
SERVICE_PRECONDITION: "hive-metastore:9083"
ports:
- "10000:10000"
hive-metastore:
image: bde2020/hive:2.3.2-postgresql-metastore
volumes:
- /data/tools:/tools
env_file:
- ./hadoop-hive.env
command: /opt/hive/bin/hive --service metastore
environment:
SERVICE_PRECONDITION: "namenode:50070 datanode:50075 hive-metastore-postgresql:5432"
ports:
- "9083:9083"
hive-metastore-postgresql:
image: bde2020/hive-metastore-postgresql:2.3.0
volumes:
- /data/tools:/tools
presto-coordinator:
image: shawnzhu/prestodb:0.181
volumes:
- /data/tools:/tools
ports:
- "8080:8080"
2.创建测试文本
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin
3,lihua,music-book,heilongjiang2:haerbin2
3,lihua,music-book,heilongjiang3:haerbin3
3.启动并连接HIVE服务。
docker-compose up -d
docker-compose exec hive-server bash
/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000

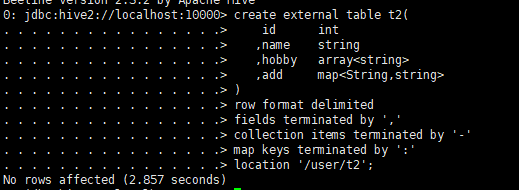
4.创建外部表
create external table t2(
id int
,name string
,hobby array
,add map
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/user/t2'
5.文件上传到上步骤中的目录内。
方法1:在HIVE的beeline终端中采用:
load data local inpath ‘/tools/example.txt’ overwrite into table t2; 删除已经存在的所有文件,然后写入新的文件。
load data local inpath ‘/tools/example.txt’ into table t2; 在目录中加入新的文件【差异在overwrite】。
方法2:用hadoop fs -put的文件上传功能。
hadoop fs -put /tools/example.txt /user/t2 文件名不改变。
hadoop fs -put /tools/example.txt /user/t2/1.txt 文件名为1.txt
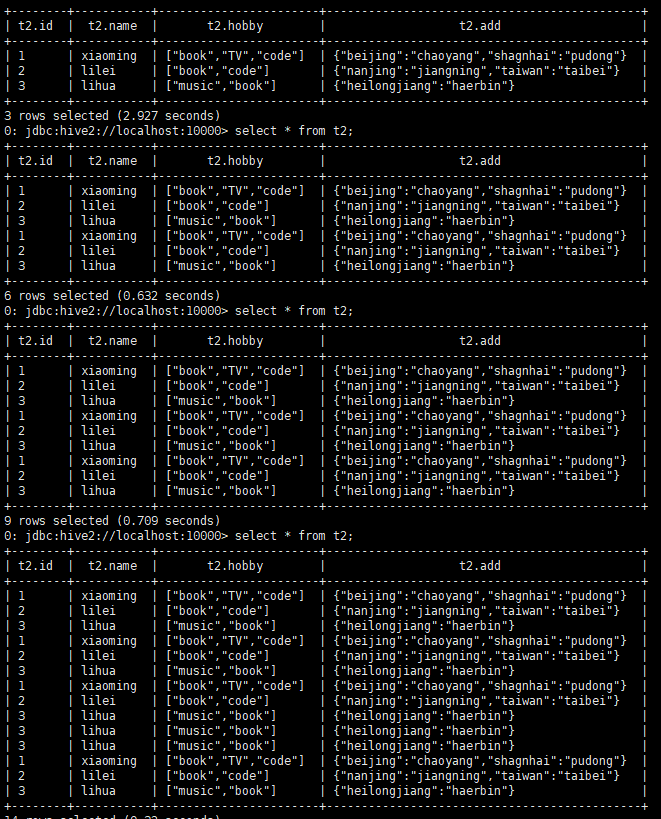
6.在HIVE命令行中验证
select * from t2; 上传一次文件,执行一次。
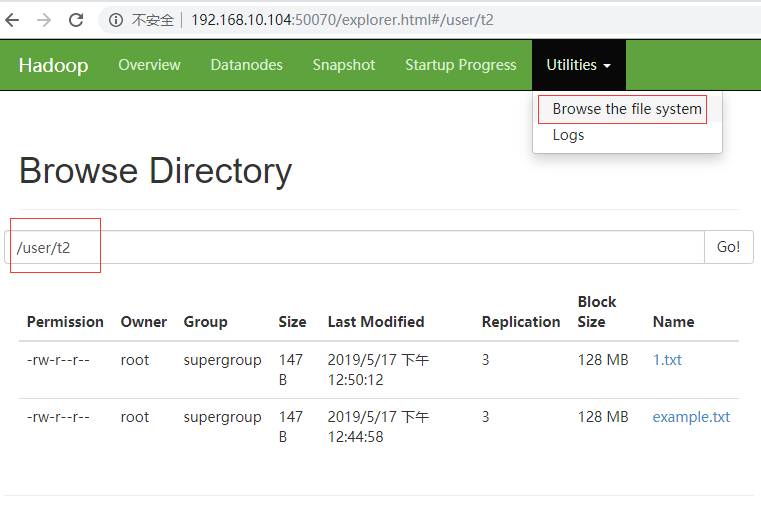
7.在hadoop的文件管理器,也可以浏览到新上传的文件。
同一个文件中的记录是会自动作去重处理的。
——————————————-
如果是sequencefile呢?
1.检验sequencefile的内容。
hadoop fs -Dfs.default.name=file:/// -text /tools/mytest.gzip.sf 废弃的
hadoop fs -Dfs.defaultFS=file:/// -text /tools/mytest.txt.sf
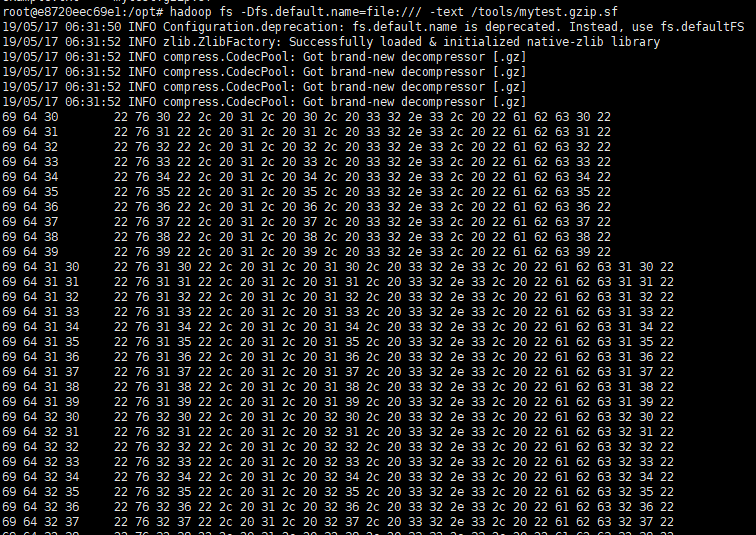
实际内容是:
2.建表
create external table sfgz(
`idx` string,
`userid` string,
`flag` string,
`count` string,
`value` string,
`memo` string)
partitioned by (dt string)
row format delimited fields terminated by ','
stored as sequencefile
location '/user/sfgz';
3.上传文件
方法一:
hadoop fs -mkdir -p /user/sfgz/dt=2010-05-06/
hadoop fs -put /tools/mytest.txt.sf /user/sfgz/dt=2019-05-17
hadoop fs -put /tools/mytest.txt.sf /user/sfgz/dt=2010-05-04
这种方法,还需要人为Reload一下才行,其reload指令是:
方法二:
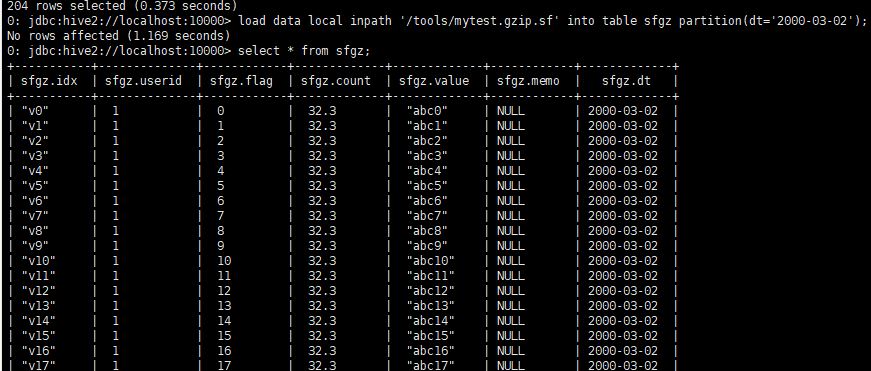
load data local inpath '/tools/mytest.txt.sf' into table sfgz partition(dt='2009-03-01');这种方法是可以直接查询了。
load data local inpath '/tools/mytest.gzip.sf' into table sfgz partition(dt='2000-03-02');