关于HBase在python上的开发环境配置和测试,在网上虽然有较多的描述,但描述的得太简单,再者很多初学者第一次接触hbase+hdfs这种大数据架构时,可能还没有走到测试这步,就已经累死在集群配置上了,为此想在进行测试相关功能前,本人简单的总结一下,自已遇到的问题以及解决办法。
-
选择合适的兼容的版本,关于版本的兼容性问题,请参照以下官方网址:
https://hbase.apache.org/book/configuration.html#hadoop
选择合适配置参考教程,本人在配置过程中耗费很多时间,原因就是教程选择,不是选择错了,就是选择得太简单,从而导致无法正确运行集群,本人为此分享个网盘资源(网盘http://pan.baidu.com/s/1c0haT9I),以供参考。
免密码登录配置:此为集群必须设置的第一步。原因是启动集群时,在各集群的主处理器调用xxx.sh文件,会间接调用ssh命令登录从处理器,有空的人仔细可以分析一下各.sh的配置文件的关系,本人以hbase的配置文件简单描述一下调用顺序关系。
Start-hbase.sh调用hbase-daemons.sh,然后hbase-daemons.sh又调用zookeepers.sh和regionservers.sh以及master-backup.sh配置文件,在这三个文件中,就会调用ssh命令登录从处理器,如图所示。
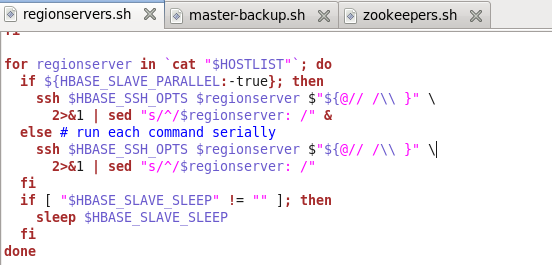
Hdfs的配置文件调用关系和hbase的类似。
安装顺序:先是安装Hadoop,然后是HBase。依照网盘的教程,配置集群。请注意配置Hadoop1和Hadoop2是有差别的,两种配置不要混淆。
-
配置完成后,使用Hbase shell命令进行测试时,可能会报一些奇怪的错误如下图为其中一种表现情况

这问题主要是Hadoop的扩展库和HBase的扩展库,使用了不同版本导致,一般情况下使用较新的版本替换旧的版本。
——————————————————————————————————-
现在开始描述python的环境配置。
-
安装thrift库,有两种方法。
方法一:yum install thrift.
方法二:下载thrift源码编译安装,此方法较复杂,网上也有很多介绍,本人也尝试了好几次,才正确编译出来。
-
生成hbase库,也有两种方法。
方法一:直接使用现成的,这方法是本人偶然发现hbase的源代码的example目录下发现的。
检查hbase的源目录
hbase-0.98.9\hbase-examples\src\main\python\thrift1\gen-by
hbase-0.98.9\hbase-examples\src\main\python\thrift2\gen-by
方法二:使用thrift源码编译出来的thrift执行文件,然后进入hbase的源码目录,按以下命令生成
cd hbase-0.98.9\hbase-thrift\src\main\resources\org\apache\hadoop\hbase\thrift && thrift –gen py Hbase.thrift
或cd hbase-0.98.9\hbase-thrift\src\main\resources\org\apache\hadoop\hbase\thrift2 &&
thrift –gen py hbase.thrift
-
实例测试
网盘http://pan.baidu.com/s/1c0haT9I,解压example文件,有如下文件:

严格按照以下顺序启动集群和测试,否则有可能会出现连接不通问题。
启动hadoop集群:start-all.sh
启动hbase集群: start-hbase.sh
启动thrift1服务端:hbase-daemon.sh start thrift,进行测试thrift1和thrift3例子。
启动thrift2服务端:hbase-daemon.sh start thrift2,进行测试thrift2的例子。
注:thrift默认的监听端口是9090,如果thrift的端口被占用,可以用netstat -tunlp | grep 9090进行检查端口被谁占用