1.配置nginx的日志格式
log_format appstore escape=json '{"@timestamp":"$time_iso8601",'
'"@source":"$server_addr",'
'"hostname":"$hostname",'
'"xforward":"$http_x_forwarded_for",'
'"remoteaddr":"$remote_addr",'
'"method":"$request_method",'
'"scheme":"$scheme",'
'"domain":"$server_name",'
'"referer":"$http_referer",'
'"url":"$request_uri",'
'"args":"$args",'
'"requestbody":"$request_body",' #根据实际情况开放,否则会导致内容太大。
'"bodybytessend":$body_bytes_sent,'
'"status":$status,'
'"requesttime":$request_time,'
'"upstreamtime":"$upstream_response_time",' #需要加引号,某些upstream放弃处理时,其时间会为空的。
'"upstreamaddr":"$upstream_addr",'
'"useragent":"$http_user_agent"'
'}';
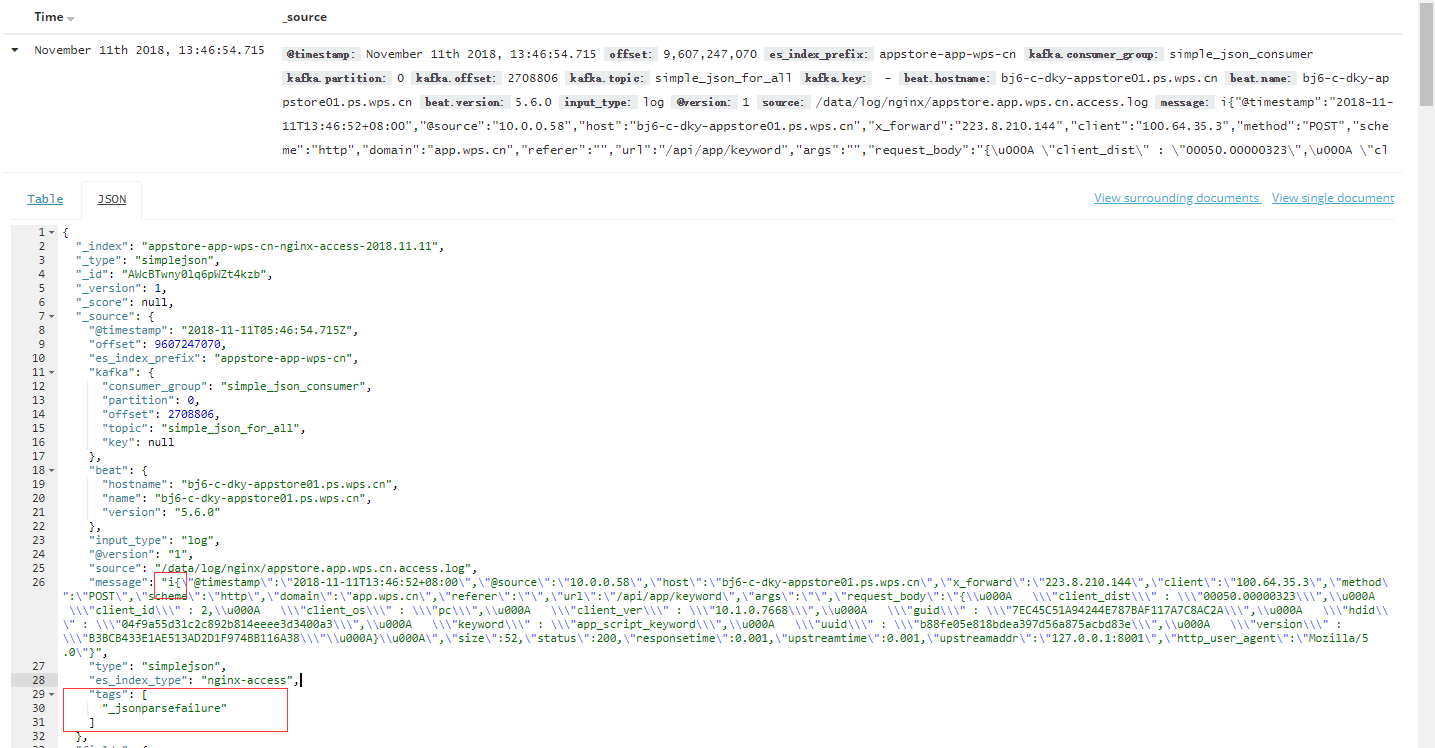
当输出的不是JSON格式时,因为logstash的透传关系,仍会把内容保存在ES中,并增加了[tag]failure的标签,如下所示:
2.使用方式
location /api/app/ {
access_log /data/log/nginx/appstore.app.abc.cn.access.log abc buffer=32k flush=5s;
error_log /data/log/nginx/appstore.app.abc.cn.error.log;
proxy_pass http://appstore.app.abc.cn:8001/;
}
3.配置filebeat的yml配置
vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- /data/log/nginx/appstore.app.wps.cn.access.log
document_type: simplejson
fields_under_root: true
fields:
es_index_type: nginx-access
es_index_prefix: appstore-app-wps-cn
tail_files: true
#================================ Processors ===================================
processors:
- drop_event:
when:
contains:
message: "HEAD /lb_health.php"
#----------------------------- output ----------------------------------
output.kafka:
hosts: ["10.0.0.33:9092","10.0.0.59:9092","10.0.0.67:9092"]
topic: "simple_json_for_all"
partition.round_robin:
reachable_only: false
required_acks: 0
compression: none
max_message_bytes: 1000000
#----------------------------- file output for debug ----------------------------------
output.file:
# true: will output to file, false: disable output to file.
enabled: false
path: "/data/log/filebeat"
filename: debug.log
#================================ Logging =====================================
logging.level: info
3.logstash的logstash.conf的nginx-access的配置。
input {
kafka {
bootstrap_servers => "10.0.0.33:9092,10.0.0.59:9092,10.0.0.67:9092"
topics => ["simple_json_for_all"]
group_id => "simple_json_consumer"
consumer_threads => 5
codec => 'json'
decorate_events => true
}
}
filter {
if [type] == "simplejson" {
json {
source => "message"
remove_field => ["message"]
remove_field => ["kafka"]
remove_field => ["beat"]
}
}
}
output {
#stdout{codec=>rubydebug}
if [type] == "simplejson" {
if [es_index_prefix] and [es_index_type] {
elasticsearch {
hosts => ["10.2.1.2:9200", "10.2.1.11:9200", "10.2.1.15:9200"]
# es_index_prefix & es_index_type were defined in filebeat.yml
index => "%{es_index_prefix}-%{es_index_type}-%{+YYYY.MM.dd}"
manage_template => true
}
} else {
elasticsearch {
hosts => ["10.2.1.2:9200", "10.2.1.11:9200", "10.2.1.15:9200"]
index => "default-simplejson-%{+YYYY.MM.dd}"
manage_template => true
}
}
}
}
5.检验索引是否存在
curl -XGET ‘http://10.2.1.2:9200/_cat/indices?v’|grep nginx-access